觀迎來到第九天,今天要進入動態網站爬蟲。首先要先理解什麼是動態網站?又和靜態網站之間有什麼差異?
靜態網站與動態網站的差異亦可以理解為同步與非同步,靜態網站再完成一個請求與回應後,客戶端即不再與伺服器有任何的交流,而動態網站則不同,當客戶端完成第一次請求後,會透過非同步的方式依照使用者的行為不斷的與伺服器進行交流。我們可以簡單地從觀察 URL 的方式去粗略的解讀該網站是否為動態網站,以 IT 邦幫忙為例,每一篇文章都有一個相對應的 URL,因此不管是在你的電腦上輸入該網址,或者在你朋友的電腦上輸入該網址,你們所看到的內容皆相同。而動態網站呢?在同樣的 URL 底下會依照使用者的行為有不同的內容,舉一個最簡單的例子 - Facebook,每個人的 Facebook 頁面的網址皆為 https://www.facebook.com/ ,但為什麼你開的頁面,跟你朋友開的頁面會不同呢?因為該頁面會透過非同步的方式不斷與伺服器進行溝通,以 Facebook 為例他的交流內容可能就是你的登入資訊,每個人的登入資訊不同,因此同樣都是 https://www.facebook.com/ ,但在瀏覽器上卻是截然不同的內容。
面對動態網站時,我們可以透過模擬 XML 的請求方式得到所需資訊,例如 Silicon Jungles 這家知名的新加坡公司官網,我們會觀察到在官網輸入 ls 指令後會有一個 XML 請求的產生,並於官網顯示該網站的目次。

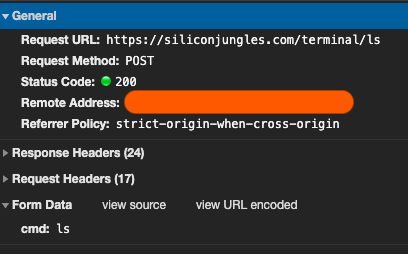
因此我們可以透過 python 模擬這個請求得到我們需要的資訊,會發現得到的回應是一個 json 格式的資料,因此透過 response.json 進行解析得到了 about.txt <br> env.txt <br> jobs.txt <br> contact.txt 的資料,符合我們在官網上所看到的資訊。
import requests
url = "https://siliconjungles.com/terminal/ls"
response = requests.post(url,data={"cmd":"ls",})
print(response.json()['type'])
# about.txt <br> env.txt <br> jobs.txt <br> contact.txt
但通常動態網站不會只有單純一個 XML 的請求,甚至有許多是 Js 選染的結果,假如例如利用 request.get 訪問 https://google.com 會發現在 response 中完全找不到 "登入" 這個名字。因此我們需要透過 Selenium 進行動態網站的爬蟲,Selenium 的架構與邏輯如下
selenium 模組控制 webdriver(瀏覽器)selenium 模組pip install selenium
讓我們透過 Selenium 進行第一次的請求
from selenium import webdriver
driver = webdriver.Chrome(executable_path = "webdriver 的位置")
driver.get("http://www.google.com")
driver.close()
你會發現有一個全新的 Chrome 視窗跳出,並在成功地顯示出 Google 首頁!
我們將從明天開始正式爬取動態網站。明天見!

